🚀 أصبحت CloudSek أول شركة للأمن السيبراني من أصل هندي تتلقى استثمارات منها
اقرأ المزيد

MCP servers have become one of the fastest-growing parts of the enterprise AI attack surface. They give AI agents direct access to tools, APIs, databases, and files. That makes AI more powerful, but it also turns a single misconfigured MCP server into an entry point for attackers. A real attack chain often starts with an open MCP server, moves to credential extraction, and ends in a database breach.
This guide explains what MCP security is, how MCP architecture works, the most common MCP security risks, the controls that reduce them, and how to monitor MCP environments for signs of attack.
MCP security protects Model Context Protocol environments, AI-agent interactions, tools, and connected systems from unauthorized access, data exposure, and malicious activity.
The Model Context Protocol (MCP) is an open standard, introduced by Anthropic in late 2024, that lets AI models and AI agents work with external tools, APIs, databases, files, and services. Instead of running in isolation, AI systems use MCP to fetch information, run actions, and exchange context with the systems around them.
This setup makes AI more useful. It also creates a new security problem. AI agents now have direct access to external systems and sensitive data through MCP. If those connections are not secured properly, attackers can manipulate prompts, abuse permissions, or reach confidential information through the AI workflow itself.
MCP security covers every layer of that workflow. It includes securing MCP servers, validating prompts and context, controlling tool permissions, protecting credentials, and monitoring AI-agent activity. Strong MCP security reduces prompt injection, unauthorized tool execution, credential leakage, and AI-driven attack paths.
MCP follows a simple request-response pattern, with context exchanged at each step.
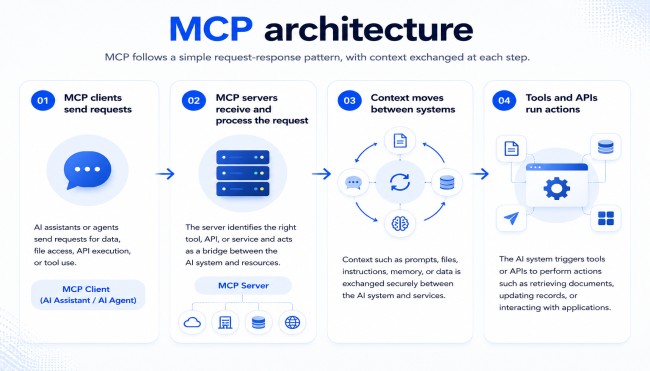
The process begins when an AI assistant or AI agent sends a request for data, file access, API execution, or tool use. The AI system acts as the MCP client. For example, an AI assistant may ask for customer records from a database or ask an external tool to generate a report.
The MCP server receives the request and identifies which tool, API, or service should answer it. The server is the bridge between the AI system and external resources. MCP servers connect to cloud platforms, enterprise applications, internal databases, and external APIs. They control which tools and information are reachable from the AI side.
Once the server processes the request, context flows between the AI system and the connected service. This context can include prompts, files, instructions, memory, or retrieved data. The AI model uses this context to understand the task and generate a response or action. Secure context exchange matters because manipulated prompts or unsafe inputs can change AI behavior.
After receiving the context, the AI system triggers tools or APIs to do something. Common actions include retrieving documents, updating records, sending requests, or interacting with applications. Tool execution is what makes MCP useful, and also what makes it risky. Excessive permissions or weak integrations turn each tool call into a potential attack path.
MCP environments introduce risks across prompts, APIs, plugins, credentials, and AI-agent execution. These are the most common MCP risks:
Prompt injection attacks place malicious instructions into prompts, files, websites, or external data that the AI system reads. The injected content overrides the AI's normal instructions and can force it to ignore security controls, reveal sensitive data, or run unauthorized commands. Because MCP relies on context exchange, insecure prompt handling is one of the largest MCP security risks.
Tool poisoning attacks change the MCP server tool definitions or function descriptions to redirect AI agent behavior. A poisoned tool can route agent actions to attacker-controlled outcomes, including data exfiltration and privilege escalation, without changing the AI model itself. Tool poisoning is unique to MCP environments and invisible to traditional security tools.
AI agents often get broad access to tools, APIs, and enterprise systems. When an AI workflow is compromised, attackers can use those permissions to retrieve confidential data, modify records, or interact with sensitive systems. Limiting permissions reduces the impact of any single compromise.
MCP clients often ask users to approve tool actions or permission requests. A malicious server can exploit this by triggering prompts repeatedly until the user stops reading and just clicks accept, granting excessive permissions or approving actions they would normally reject. The same habit lets a malicious server from an unofficial source impersonate a trusted one and get approved.
A confused deputy attack tricks an MCP server with broad privileges into performing an action for a user who should not be allowed to do it. The server acts on instructions without checking whether that specific request is authorized for that specific user, so attackers abuse the gap between what the server can do and what the user is permitted to do, reaching data and systems they could never access directly.
MCP servers act as gateways between AI systems and connected services. Weak authentication, exposed APIs, poor access controls, and unsafe configurations turn them into direct entry points. An open MCP server can expose AI tool definitions, connected systems, and cloud credentials to anyone on the internet. This is often the first step in a real-world AI attack chain.
MCP environments use API keys, authentication tokens, and service credentials to connect to external systems. Poor secret management exposes these credentials through logs, prompts, memory, or unsecured storage. Leaked credentials let attackers act as trusted services and reach sensitive resources without setting off alarms.
Many organizations connect external plugins, APIs, and MCP services to extend AI functionality. Each external integration adds supply chain exposure. A malicious third-party tool can collect sensitive data, alter AI responses, or create hidden attack paths inside the enterprise.
Data poisoning introduces false or harmful information into the AI workflow. Attackers alter context sources, training inputs, or connected data repositories to change how the AI behaves. In MCP environments, poisoned data can spread quickly across connected tools and services.
These are the controls that protect MCP environments. They work together, and no single control is enough on its own.
Authentication confirms the identity of users, AI agents, and connected services before access is granted. Authorization controls what each one is allowed to do. Multi-factor authentication, role-based access control, and least-privilege policies stop unauthorized users or compromised agents from reaching sensitive tools.
Define clear boundaries for what each AI agent can access and run. Restricting tool permissions reduces the damage from compromised prompts, malicious requests, or unsafe workflows. An AI agent that only needs read access to a single API should not have write access to ten.
Store API keys, access tokens, and service credentials in secure vaults. Never put them in prompts, logs, or source code. Rotate them on a regular schedule. Controlled access and rotation reduce the impact of any leak.
Check incoming prompts, files, instructions, and external context before they reach the AI workflow. Sanitization strips harmful instructions, suspicious content, and unsafe formatting that could trigger prompt injection. Validation is the first line of defense for both direct and indirect prompt injection.
MCP systems exchange large amounts of sensitive information between AI agents, APIs, tools, and services. Encrypt data while it moves across networks and while it sits in storage. This reduces exposure to interception and theft.
Keep AI-agent sessions isolated from each other and from critical enterprise systems. Sandboxing creates controlled execution environments where agents run with limited permissions. If one workflow is compromised, isolation stops attackers from moving across connected systems.
Define explicit trust boundaries between trusted systems and external or unverified sources. Authentication, authorization, validation, and monitoring should all operate at these boundaries. Trust boundaries are what prevent a single compromised tool from cascading into a full breach.
Continuous monitoring is what catches MCP attacks in progress. The same three-layer model used for AI attack surface monitoring (discovery, assessment, triage) applies here, with monitoring focused on MCP-specific signals.
AI agents call tools, APIs, and external services constantly. Watch for unusual behavior such as repeated API calls, unauthorized command execution, or unexpected tool use. Abnormal execution patterns often signal a compromised workflow, manipulated prompts, or permission abuse.
MCP depends heavily on prompts, memory, and context exchange. Attackers manipulate prompts or inject malicious instructions to change AI behavior. Tracking prompt and context changes helps security teams catch unusual modifications, unsafe instructions, or suspicious context injections before they affect AI decisions.
Rogue MCP servers, APIs, and integrations create hidden access paths. Detection should flag unknown MCP connections, untrusted integrations, and suspicious external communication. Catching these early reduces the risk of unauthorized access and supply chain compromise.
AI agents retrieve files, query databases, and run workflows automatically. Behavior analysis identifies risky actions, excessive permissions, and unusual execution patterns. The goal is to spot when an agent is doing something outside its normal scope.
A single suspicious event often looks harmless on its own. Correlating MCP threat signals such as odd prompts, abnormal API activity, unauthorized access attempts, and risky agent actions connects them into a larger pattern. This is how AI-driven attack paths become visible early enough to disrupt.
Traditional API security covers requests between applications. MCP security adds the AI agent layer: prompts, context exchange, tool definitions, and autonomous agent behavior. Tool poisoning and prompt injection are central to MCP, but not to API security.
No. MCP is built for interoperability, not security. It does not enforce authentication, sandboxing, or permission limits on its own. Most disclosed incidents trace back to misconfiguration, not the protocol.
It tricks a broadly privileged MCP server into acting for a user who is not authorized, letting attackers reach data they could not access directly. The 2025 GitHub MCP attack is a real example.
Disclosed in May 2025, a prompt injection on the GitHub MCP integration. A malicious public-repo issue made a user's AI assistant leak private repo data into a public pull request. A textbook confused deputy attack, not a code flaw.
Yes. EscapeRoute (CVE-2025-53109 and CVE-2025-53110) in Anthropic's Filesystem MCP server let attackers escape the file sandbox and gain read and write access to the host. Patched versions and strict path validation fix them.
Yes. A June 2025 scan found hundreds of public MCP servers, many bound to 0.0.0.0 with no authentication, sometimes called NeighborJack. Misconfiguration, not the protocol.
CloudSEK delivers MCP security monitoring through AIVigil, the AI attack surface monitoring and management platform. AIVigil is built on a three-layer engine that covers MCP environments end to end:
